AI 정부를 위한 HWP·PPT 구조분석의 디테일
안녕하세요, Document AI 기업 사이냅소프트입니다.
한국주택금융공사, S디스플레이 등에 도입되어있는 사이냅 도큐애널라이저(제품소개 링크)가 근래 관심을 받고 있습니다.
정부의 AI 학습을 위한 hwp 데이터화 추진이 이슈가 되면서인데요.
오늘은 사이냅 도큐애널라이저가 문서 구조를 분석하는 디테일이 어떻게 좋은지 설명합니다.
공공기관의 문서 AI 도입, 어디까지 왔나
2025년 현재, 공공기관의 AI 도입은 더 이상 실험 단계가 아닙니다. 행정안전부와 기획재정부가 공공기관의 AI 활용을 적극 권장하고 있으며, 국가보훈처의 RPA 도입처럼 실제 성과가 나타나기 시작했습니다.
그런데 국내 공공기관에는 특수한 상황이 있습니다. 공무원의 90% 이상이 여전히 한글(HWP) 파일과 MS Office를 주요 업무 도구로 사용합니다. 1990년대 초부터 한글이 공문서 표준 포맷으로 지정되면서 형성된 구조이기 때문입니다.
문제는 이런 문서들을 AI가 제대로 이해하느냐입니다.
OCR 방식의 실제 한계
현재 많은 문서 AI 솔루션이 다음과 같은 방식으로 작동합니다:
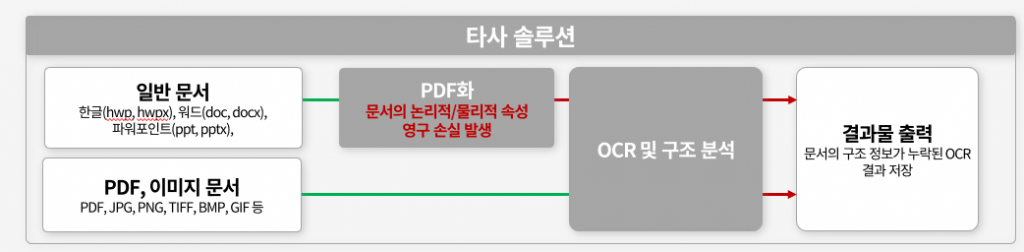
- HWP/PPT → PDF 변환
- PDF를 이미지로 인식
- OCR로 텍스트 추출
- 후처리로 구조 추론
PDF는 인쇄를 위한 ‘페이지 기술 언어’일 뿐, 문서의 논리적 구조 정보를 담고 있지 않습니다. 원본 문서가 가지고 있던 다음과 같은 중요한 정보들이 영구적으로 손실됩니다:
- 문단 계층 구조: 제목, 소제목, 본문의 논리적 관계
- 표의 셀 구조: 병합된 셀, 헤더-데이터 관계
- 차트 데이터: 그래프를 그린 원본 수치 데이터
- 도형 순서: PPT 슬라이드에서 레이어 간 선후 관계
- 수식 정보: XML 형태의 구조화된 수식 데이터
특히 공공기관에서 자주 사용하는 복잡한 표 구조의 경우, PDF 변환 후에는 단순히 선과 텍스트의 배치로만 인식됩니다. 이를 다시 복원하려면 AI가 “이 선들이 표를 이루고 있고, 이 텍스트들이 각 셀에 속한다”는 것을 추론해야 하는데, 이 과정에서 오류가 발생할 수밖에 없습니다.
사이냅 도큐애널라이저의 하이브리드 구조 분석
사이냅 도큐애널라이저의 경우 하이브리드로 분석합니다.
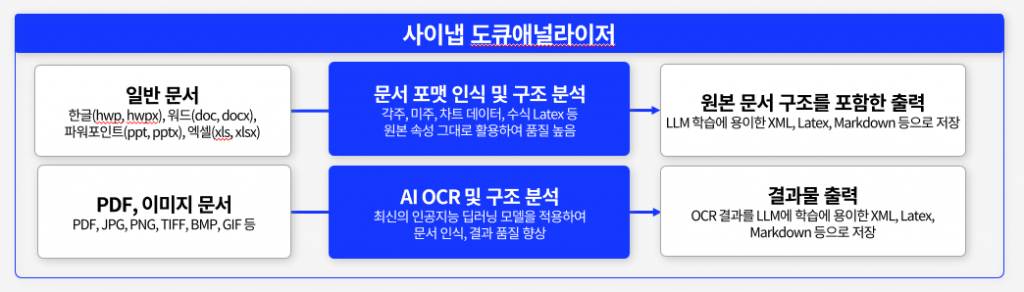
AI OCR엔진으로 분석할 뿐만 아니라 한글, 워드, 파워포인트, 엑셀 등의 문서는 사이냅만의 원본문서 구조 분석을 하는 엔진을 사용해 복합적으로 분석합니다.
사례 1: 여러 페이지에 걸친 표

공공기관 보고서에는 예산표, 사업현황표 등 긴 표가 자주 등장합니다. 원본 HWP에서는 하나의 연속된 표이지만, PDF로 변환되는 순간 각 페이지별로 끊깁니다. OCR은 각 페이지를 독립적으로 인식하기 때문에, 이를 다시 하나의 표로 연결하려면 “첫 페이지 마지막 행과 다음 페이지 첫 행이 연결되어 있다”는 것을 AI가 추론해야 합니다. 이 과정에서 오류가 발생하거나, 아예 별개의 표로 인식되는 경우가 많습니다.
사이냅 도큐애널라이저는 한글, 워드 문서에서 페이지가 분리되어있지만 실은 1개인 표의 연결 정보를 제공합니다.
사례 2: 복잡한 셀 구조
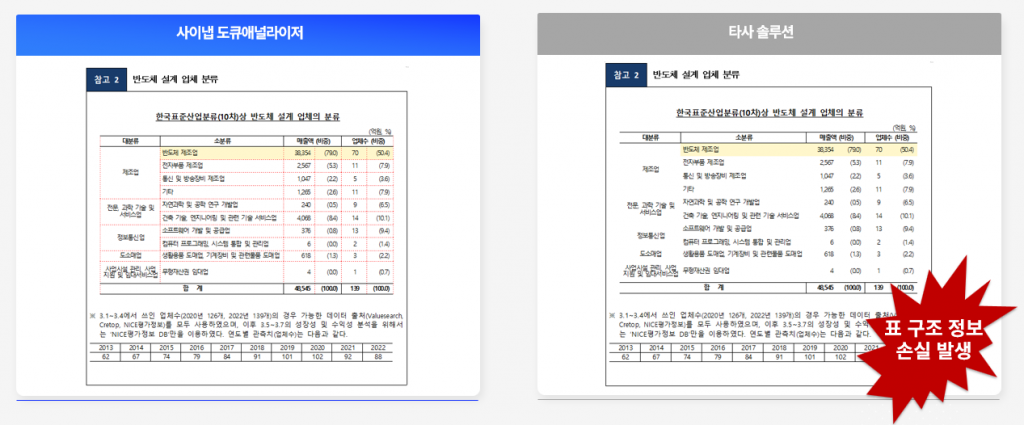
PPT 슬라이드나 공문서 작성 시 레이아웃을 맞추기 위해 투명한 표를 자주 사용합니다. 시각적으로는 깔끔하게 정렬된 텍스트처럼 보이지만, 실제로는 테두리를 투명(none)으로 설정한 표 구조입니다.
문제는 이 문서를 PDF로 변환하면 “선이 없는 텍스트 배치”로만 보인다는 점입니다. OCR은 이미지에서 선을 찾아 표를 인식하는데, 투명한 표는 선 자체가 없으니 그냥 여러 개의 텍스트 박스가 배치된 것으로 인식합니다. 따라서:
- 표의 행과 열 구조를 파악할 수 없습니다
- 어떤 데이터가 같은 행에 속하는지 추론해야 합니다
- 텍스트 간 위치 관계만으로 추측하다 보니 정렬이 미묘하게 어긋나면 오인식합니다
반면 사이냅 도큐애널라이저가 원본 파일을 직접 분석하면, 파일 내부에는 “표” 객체로 명확히 저장되어 있습니다.
단지 테두리 속성이 “투명”으로 설정되어 있을 뿐입니다. 따라서 셀의 행·열 정보, 데이터 간 관계를 정확히 추출할 수 있습니다.
공공기관의 프레젠테이션 자료나 보고서에서 이런 투명한 표가 매우 자주 사용되기 때문에, 실무적으로 체감되는 차이가 큽니다.
사례 3: PPT 차트의 원본 데이터

슬라이드의 그래프를 분석할 때, OCR 방식은 이미지로 변환된 그래프를 “보고” 수치를 읽습니다. 막대 높이나 꺾은선을 시각적으로 판단해서 “약 23 정도”라고 추정하는 식입니다. 그래프가 복잡하거나 수치 레이블이 겹치면 오인식 확률이 높아집니다.
사이냅 도큐애널라이저는 원본 PPT 파일을 직접 파싱하기 때문에 세 가지를 동시에 추출합니다:
- 차트 데이터: 그래프를 그린 실제 수치를 XML에서 추출 (예: “2023년 42.8, 2024년 50.8, 2025년 76.2”)
- 차트 이미지: 차트를 별도 이미지 파일로 저장하여 Vision-Language Model 활용 가능
- 캡션 및 메타정보: 차트 제목, 범례, 축 레이블, 출처를 구조화된 형태로 추출
OCR이 “그래프에서 대략 23이라는 숫자를 읽었다”는 수준이라면, 도큐애널라이저는 “2024년 매출액 정확히 23.7억 원, 전년 대비 15% 증가”라는 완전한 정보를 제공합니다.
사례 4. 유니코드 텍스트 추출
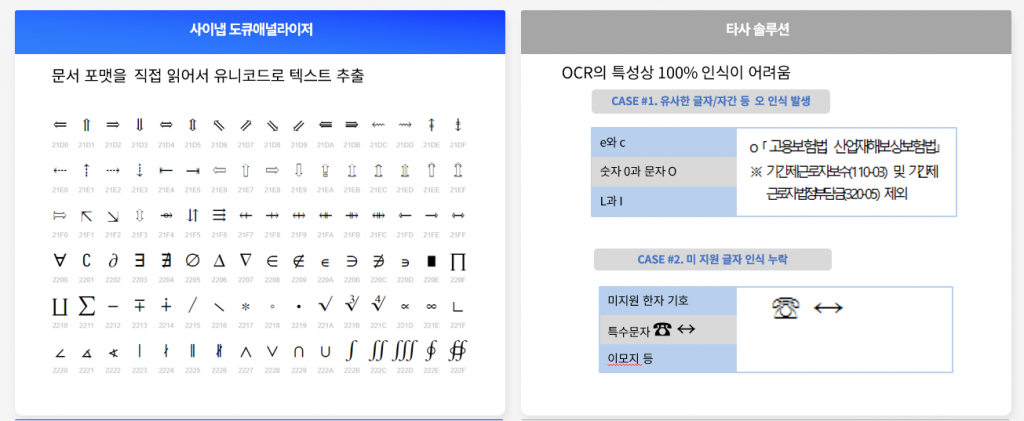
OCR은 이미지를 보고 “이 모양이 이 글자일 것이다”라고 추정하는 방식입니다. 일반적인 한글이나 영문은 인식률이 높지만, 특수문자는 문제가 됩니다.
공문서에 자주 등장하는 문자들을 예로 들면:
- 항목 표시: ㉮㉯㉰, ①②③, ⓐⓑⓒ
- 법률 기호: §(섹션), ¶(단락), ※(참고)
- 단위 기호: ㎡, ㎏, ℃, ㎜
- 특수 한자: 行政, 豫算, 處理
OCR은 이런 문자들을 이미지로 보고 인식하려다 보니 “ㄱ)”으로 잘못 읽거나, 아예 인식하지 못하고 누락시키는 경우가 많습니다. 특히 스캔 품질이 좋지 않거나 폰트가 작을 때 문제가 심각합니다.
반면 HWP, DOCX, PPTX 파일 내부에는 모든 텍스트가 유니코드로 저장되어 있습니다. 사이냅 도큐애널라이저는 파일 포맷을 직접 파싱하기 때문에 이 유니코드 문자를 그대로 추출합니다. 추정이나 인식 과정이 없으므로 특수문자, 한자, 수식 기호 모두 100% 정확하게 가져올 수 있습니다.
공공기관에서 문서를 검색하거나 RAG 시스템에 활용할 때, “제3조 ㉮항”이 정확히 인식되느냐 마느냐는 실무적으로 중요한 차이입니다.
정리하며
공공기관의 문서는 정책 수립과 행정 서비스의 기반이 되는 지식 자산입니다. 하지만 HWP와 MS Office 문서 안에 있는 이 지식들이 AI가 제대로 이해할 수 없는 형태라면, 디지털 전환의 효과는 제한적일 수밖에 없습니다.
OCR 방식도 계속 발전하고 있지만, 원본 문서가 가진 구조 정보를 이미 잃어버린 상태에서 시작한다는 근본적인 한계가 있습니다. PDF 변환 없이 원본 포맷을 직접 해석하는 방식은 이 한계를 피해갈 수 있는 접근법입니다.
사이냅 도큐애널라이저를 사용하는 기관들이 늘고 있는 이유도 여기에 있습니다. 문서를 “이미지로 보고 텍스트를 읽는” 것이 아니라, “구조를 이해하고 맥락을 파악하는” 것. 이 차이가 실제 업무에서 체감되는 정확도와 효율성의 차이로 나타납니다.

