
AI 진로상담, 데이터를 제대로 읽지 못하면 시작도 못 한다
안녕하세요, Document AI 전문기업 사이냅소프트입니다.
KERIS ‘맞춤형 진로 상담 지원 방안’ 보고서
얼마 전부터 한국교육학술정보원(KERIS)이 발간한 연구 보고서
<맞춤형 진로·진학·상담 지원을 위한 에이전틱 AI 적용 방안 연구>가 한국교육 신문 등 교육 현장에서 주목받고 있습니다.

진로 진학 상담 지원을 위한 에이전틱 AI 워크플로우 설계
이 보고서는 AI가 학생의 학업 이력, 활동 기록, 성적 데이터를 분석해 교사의 진로·진학 상담을 보조하는 시스템의 구체적인 요구사항을 담고 있습니다. 더 이상 “AI로 교육을 혁신하자“는 선언이 아니라, 교육 전문가들이 실제로 무엇이 필요한지를 검토한 결과물이라는 점에서 의미가 다릅니다.
그런데 보고서를 읽으면서 하나의 현실적인 질문이 생깁니다.
AI가 학생 데이터를 분석하려면, 그 데이터가 AI가 읽을 수 있는 형태여야 한다는 전제가 먼저 충족돼야 하지 않을까?
보고서가 요구한 것
보고서의 전문가 타당화 분석에는 이 시스템을 실제로 작동시키기 위한 두 가지 조건이 명확히 나옵니다.
첫 번째는 포맷 다양성입니다.

맞춤형 AI 진로 상담을 위한 다양한 데이터의 존재.
“PDF 외에도 이미지, 화면 캡처, 성적표 등 다양한 형식을 인식하는 파일 호환성 확대와 나이스(NEIS) 자료 가공을 위한 구체적인 가이드라인 제공이 실질적인 활용도를 높이는 장치로 강조되었다.” — RR 2025-03, p.47
두 번째는 근거 기반 설계입니다.

증거 기반(evidence-based) 설계
“모든 결과에 구체적인 근거와 출처를 명시하는 ‘증거 기반(evidence-based)’ 설계는 정량 분석에서 나타난 신뢰성 우려를 해소하고, 교사가 결과를 재해석하여 설명하는 데 필수적인 요소로 지목되었다.” — RR 2025-03, p.46
포맷 다양성은 입력의 문제고, 근거 기반 설계는 출력의 문제입니다. 두 조건을 모두 충족해야 교사가 실제로 믿고 쓸 수 있는 진로상담 AI가 됩니다.
현장의 현실, 학생 데이터는 포맷이 제각각이다
실제 학교 현장에서 한 학생을 둘러싼 데이터가 어떤 모습인지 들여다보면, 왜 포맷 다양성이 첫 번째 조건으로 꼽혔는지 이해가 됩니다.
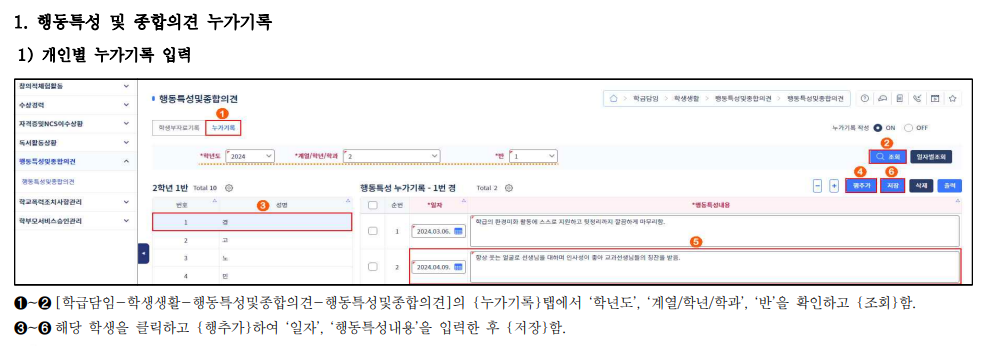
4세대 나이스에 행동특성 및 종합의견 누가기록을 직접 등록하는 예시
학생부 본체는 교사를 통해 교육부 4세대 NEIS(나이스, 교육행정정보시스템)에 직접 입력됩니다. 칼럼과 내용이 매치되는 정형 서식으로 활용도가 높다고 생각하지만 그렇지 않은 데이터일 때도 있습니다.
이 출력할 때의 학생부는 PDF로 출력됩니다. 교사가 학생부 작성 시 참고하는 기재요령과 서식은 한컴오피스(.hwp) 파일로 배포됩니다.

나이스 외에 수기관리, 별도 관리 되는 상담 데이터
상담의 수기데이터나 개별 파일 문서, 여기에 화면 캡처나 NEIS 출력물까지 더해지면, 한 학생에 관한 데이터가 정형서식 외에도 다양하게 소화가 되어야합니다.
이 모든 자료를 AI가 정확히 처리하지 못하면, 진로상담 AI는 제한된 데이터만 보고 판단하거나 일부 포맷을 억지로 변환하는 과정에서 정보를 잃게 됩니다.
포맷 문제, 왜 쉽게 해결이 안 되나
가장 흔한 접근은 모든 자료를 PDF로 통일한 뒤 처리하는 방식입니다. 하지만 이 방법에는 구분해서 봐야 할 두 가지 경우가 있습니다.

스캔된 PDF는 이미지로, 이를 변환하는 OCR의 품질이 중요
스캔된 성적표, 화면 캡처처럼 이미지 기반 파일은 PDF로 변환해도 내부가 여전히 이미지입니다. 텍스트로 인식시키려면 OCR이 필요한데, 품질이 낮으면 성적 수치가 뒤바뀌거나 항목 기호(①②③)가 누락됩니다.
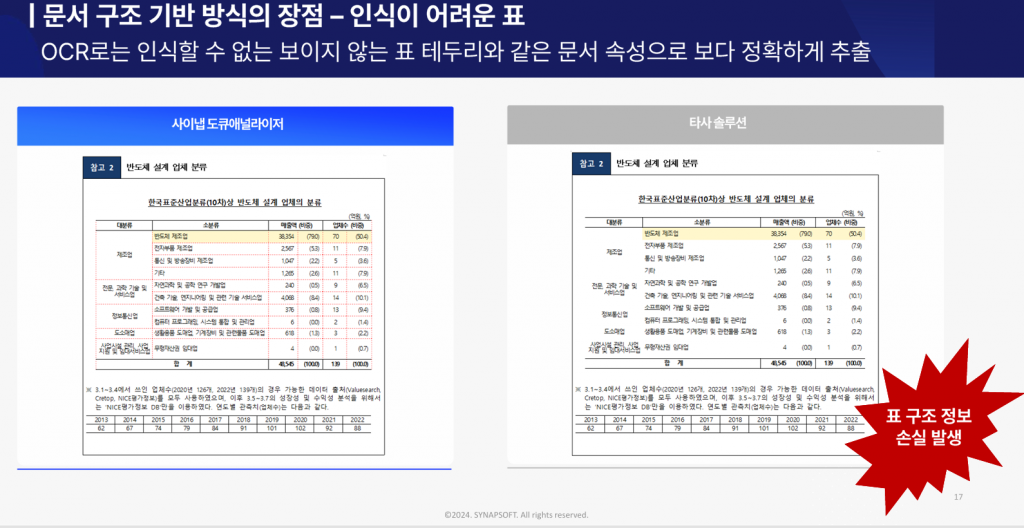
문서구조 추출_사이냅 도큐애널라이저와 타사 솔루션
반면 리더블 PDF나 HWP처럼 내부에 텍스트와 구조 정보가 있는 파일은 OCR이 필요 없지만 다른 문제가 생깁니다. PDF 변환을 거치면 표의 행·열 관계가 무너지고 맥락이 끊깁니다. “2학년 1학기 수학 3등급“이라는 정보가 어느 학기의 어느 과목인지 연결이 사라지는 식입니다.
두 경우 모두 제대로 처리되지 않으면, 이후 모든 분석이 흔들립니다.
어떤 포맷이든 정확하게 구조분석을 하는 사이냅 도큐애널라이저
사이냅 도큐애널라이저는 이 두 가지 경우를 하나의 솔루션에서 처리합니다.
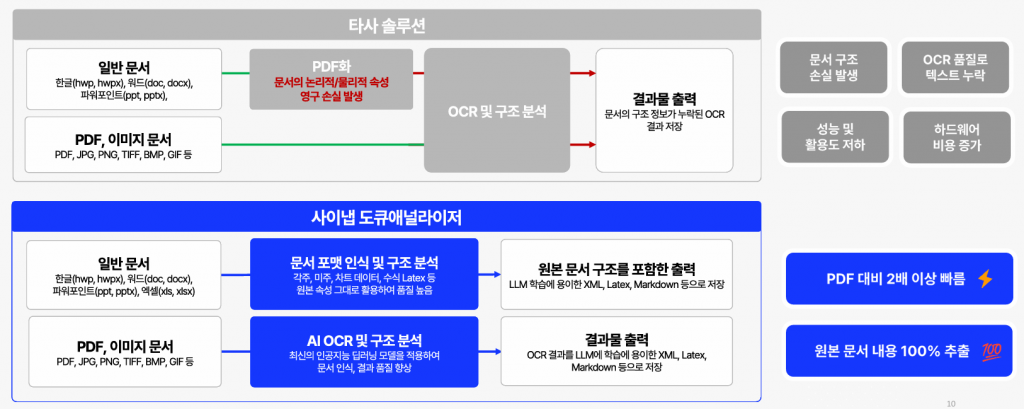
사이냅 도큐애널라이저
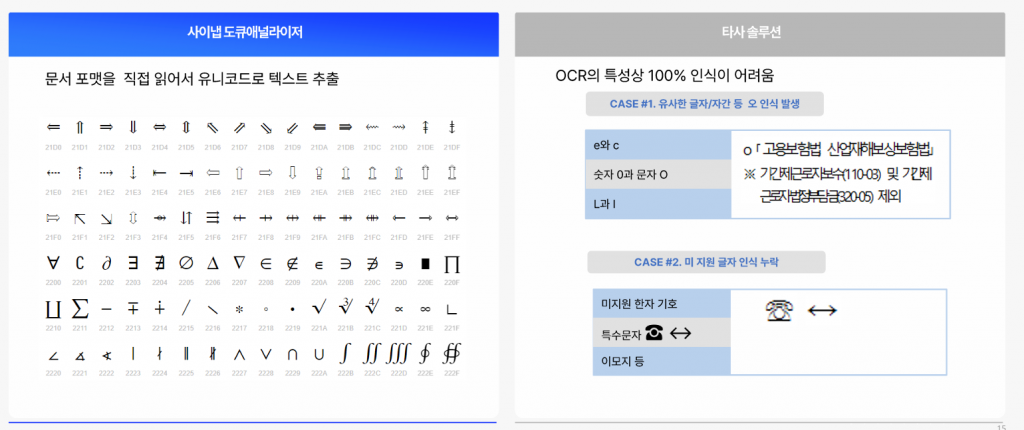
사이냅도큐애널라이저hwp, hwpx의 글자 인식
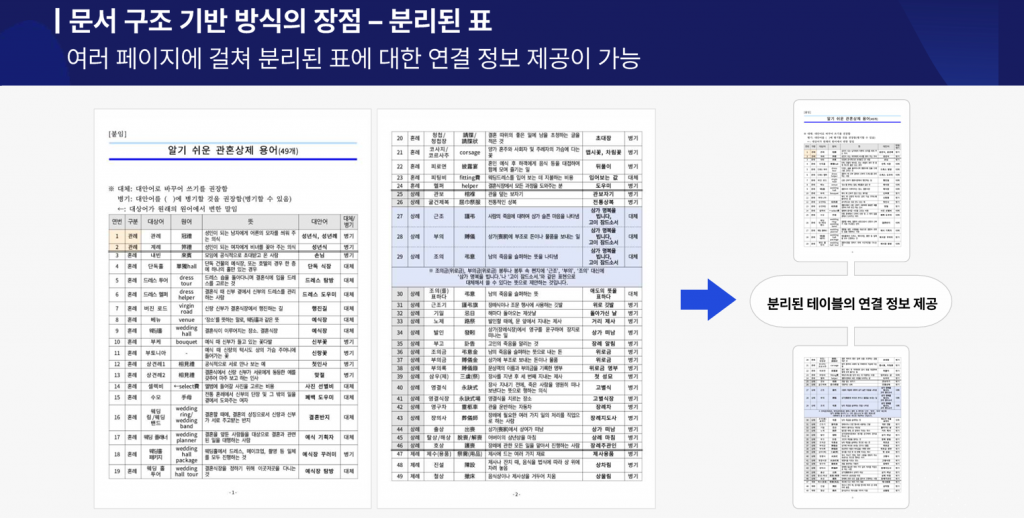
사이냅 도큐애널라이저 분리된 표 구조 정보 제공
HWP, HWPX, DOCS, DOCX처럼 원본 구조가 있는 파일은 포맷을 직접 파싱합니다. PDF 변환 없이 원본 그대로 읽기 때문에 표의 셀 구조, 문단 계층, 메타데이터(작성자·작성일 등)가 손실 없이 보존됩니다. 여러 페이지에 걸친 성적 표도 끊기지 않고 하나의 연속된 데이터로 인식합니다.

TTA 인증 한글 인식률 99.3%
PDF, 이미지나 스캔 파일처럼 시각 정보로만 이루어진 자료는 내장된 OCR 엔진이 처리합니다. 사이냅소프트의 OCR 기술은 한국정보통신기술협회(TTA) 인증 기준 공공행정문서 인식률 99.3%를 달성했으며, 표 구조와 ①②③ 같은 특수기호도 정확하게 인식합니다. 원본 구조 파싱과 OCR을 하이브리드로 결합하기 때문에, 입력 포맷이 무엇이든 일관된 품질의 구조화 데이터로 변환됩니다.
분석된 결과는 Markdown, JSON, XML 등 AI가 바로 소화할 수 있는 형태로 출력됩니다. 학생 성적 데이터가 “2학년 1학기, 수학, 3등급, 원점수 72점“처럼 정확하게 정형화된다는 의미입니다.
근거를 보여주는 AI, 사이냅 어시스턴트
데이터를 정확하게 읽는 것과, 교사가 신뢰할 수 있는 답변을 내놓는 것은 별개의 문제입니다.
보고서는 “교사가 결과를 재해석하여 설명할 수 있어야 한다“고 강조했습니다. AI가 결론만 제시하는 것이 아니라, 그 결론의 근거를 교사가 직접 확인할 수 있어야 한다는 의미입니다.
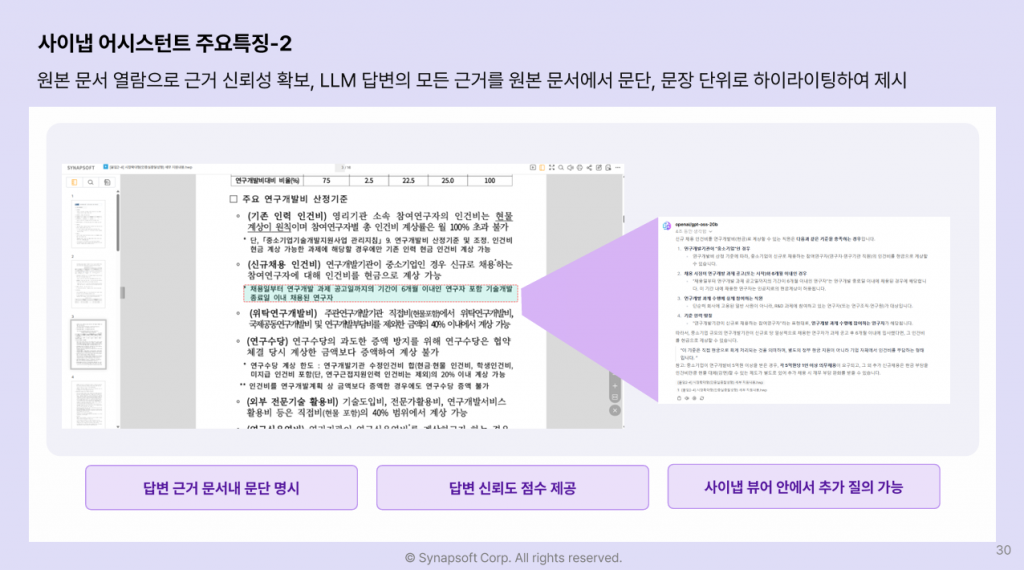
사이냅 어시스턴트는 Agentic RAG 기반으로 동작하며, 답변을 제시할 때 해당 내용이 어느 문서의 어느 부분에서 나온 것인지 원본 문서 위에 하이라이팅으로 표시합니다. “이 학생은 2학년 이후 수학 성취도가 꾸준히 향상되었습니다“라는 분석이 있다면, 그 판단의 근거가 된 성적 데이터 원본을 화면에서 바로 짚어줍니다.
교사는 AI의 분석을 그대로 전달하는 것이 아니라, 근거를 확인하고 자신의 전문 판단을 더해 학생에게 설명할 수 있습니다. 이것이 보고서가 말한 “AI는 교사의 전문성을 보조하고 증강하는 도구“의 실제 구현 방식입니다. 온프레미스로 운영되어 학생 개인정보가 외부 서버로 전송되지 않는 것도 교육 기관에는 중요한 조건입니다.
정리하며
KERIS의 연구가 제시한 두 조건, 다양한 포맷의 정확한 처리와 근거 기반 답변은 기술적으로 충족 가능한 수준에 와 있습니다.
다만 이 두 조건은 순서가 있습니다. 입력 데이터가 정확하게 처리되지 않으면, 아무리 정교한 AI 모델을 얹어도 교사가 신뢰할 수 있는 결과는 나오지 않습니다. 진로상담 AI의 신뢰도는 모델의 성능보다 데이터를 얼마나 정확하게 읽느냐에서 먼저 결정됩니다.
이번 이야기는 학교 현실로 성큼 다가온 RAG와 AI Agent를 이용한 진로 상담에 대한 연구를 살펴보았고, 연구에서의 AI Agent가 조금 더 기술적 보완에 대한 지점을 FGI를 통해 제시했기 때문에, 예시로 이러한 부분에서 사이냅 도큐애널라이저와 사이냅 어시스턴트가 어떤 방식으로 쓰이는지 정리해보았습니다. 진로 상담 뿐만 아니라 공공, 기업에서 축적된 문서 데이터를 바탕으로 AI Agent를 활용할 수 있는 방안은 많습니다.
관련해서 문의가 필요하신 경우 https://www.synapsoft.co.kr/contact/ 를 통해 문의해주세요. 감사합니다.

