
[기술블로그] EP6. AWS EKS 비용 최적화
안녕하세요! 키냅스(Kynapse)에서 백엔드 및 인프라를 담당하고 있는 개발자, 최우석입니다.
이번 글에서는 AWS EKS 환경에서 비용을 줄이고, 확장성은 높인 실제 개선 사례를 공유합니다.
Node.js 서비스 특성에 맞는 리소스 최적화부터 HPA + CA 기반 오토스케일링 구조, 그리고 운영 중 겪은 트러블슈팅까지 정리했습니다.
[EP6. 핵심 요약]
-
Node.js 특화 리소스 최적화
Node.js의 싱글 스레드 이벤트 루프 특성을 고려하여, 고사양 단일 Pod 대신 1 vCPU 단위의 경량 Pod으로 파편화하고 수평 확장(Scale-out) 효율을 극대화, 이를 통해 CPU 방치 리소스를 제거하고 실효 성능을 확보 -
인스턴스 타입 전략 (c5 → m6i)
컴퓨팅 최적화(c5)에서 범용 인스턴스(m6i)로 전환하여 CPU와 메모리 할당 비율을 1:4로 맞춤. Pod 배치 밀도를 최적화하여 빈 자원(Slack Resource) 없이 노드 수용량을 100% 활용, 결과적으로 노드당 비용 약 48% 절감 -
HPA + CA 결합 및 가용성 설계
Cluster Autoscaler(CA)만 존재하던 구조에 Horizontal Pod Autoscaler(HPA)를 도입하여 트래픽 스파이크에 즉각 대응. VPA 대신 예측 가능한 HPA를 선택하고, CPU(60%) 및 메모리(70%) 임계치를 설정하여 안정적인 확장성 구축 -
PDB 및 스케일 다운 트러블슈팅
CA의 노드 드레인 시 발생하는 서비스 중단을 방지하기 위해 minReplicas를 2 이상으로 상향하고, PDB 설정을minAvailable에서maxUnavailable: 1로 변경, 이를 통해 노드 제거 시에도 최소 1개의 가용 Pod을 상시 확보하는 안전 장치 마련
|한 명만 일하는 사무실에 책상 두 개 놓지 않기: 리소스 최적화 노트
저희 서비스는 EKS 위에서 Node.js 기반 API 서버를 운영하고 있습니다.
초기에는 넉넉하게 인스턴스를 타겟 노드 그룹으로 설정하고, Pod당 2 vCPU / 4 GB 메모리를 할당했습니다.
Cluster Autoscaler(CA)를 붙여 스케일 인/아웃은 자동화했지만, HPA는 적용하지 않은 상태였습니다.
어느 날 인프라 비용 리뷰를 하다가 한 가지 사실을 발견했습니다.
Node.js는 기본적으로 싱글 스레드입니다. 멀티 스레드를 쓰는 Worker Threads나 클러스터 모드를 사용하지 않는 이상, 아무리 많은 CPU를 할당해도 실제로는 코어 하나만 씁니다.
2코어를 할당하면서 사실상 절반의 CPU 비용을 날리고 있었던 셈입니다.

| 낭비되는 자원 구조조정: Node.js 서버의 진정한 ‘가성비’ 스펙
Pod 리소스 스펙 경량화
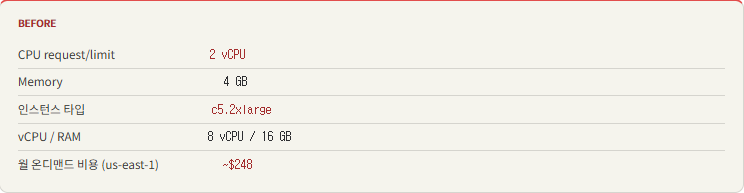
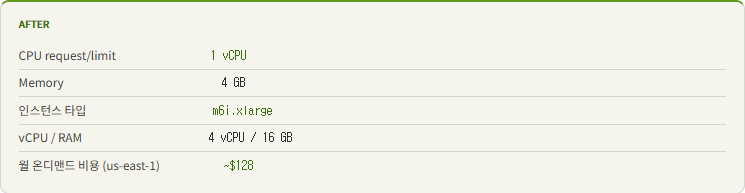

왜 c5 → m6i인가?
c5 시리즈는 컴퓨팅 최적화 인스턴스입니다. CPU:메모리 비율이 높지만, 우리 워크로드처럼 코어 1개 + 메모리 4 GB 단위로 Pod을 배치하면 CPU 자원이 남아돌아 메모리가 먼저 포화됩니다.
m6i.xlarge 는 범용(4 vCPU / 16 GB)으로, CPU:메모리 비율이 1:4라 우리 Pod 스펙(1 vCPU / 4 GB)과 정확히 맞아떨어집니다.
빈 자원 없이 노드 하나에 Pod 4개를 꽉 채울 수 있습니다.
성능 변화

즉, CPU는 절반으로 줄였지만 Node.js 싱글 스레드 입장에서는 실효 성능이 오히려 소폭 개선될 수 있습니다.
다만 동시에 CPU-intensive 작업이 몰리는 스파이크 상황에서는 코어 여유분이 없으므로 HPA를 통한 수평 확장이 더욱 중요해집니다
|밀려오는 파도에 맞서는 법: 고정된 Pod에서 유연한 HPA로
CA만 있는 상태에서는 노드 레벨의 스케일만 자동화되어 있었고, Pod 수는 고정이었습니다.
트래픽 스파이크 시 Pod이 먼저 포화되어 응답 지연이 생기는 구조였습니다. HPA를 도입해 Pod 수 자체를 자동으로 조절하도록 했습니다.
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: api-server-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: api-server
minReplicas: 2
maxReplicas: 16
metrics:
– type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 60
– type: Resource
resource:
name: memory
target:
type: Utilization
averageUtilization: 70

| 트러블슈팅: CA가 PDB를 무시하는 문제
이번 작업에서 가장 골치 아팠던 부분입니다.
PDB(PodDisruptionBudget)를 설정해 최소 1개의 Pod은 항상 유지되도록 했습니다.
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: api-server-pdb
spec:
minAvailable: 1
selector:
matchLabels:
app: api-server
그런데 CA가 노드를 스케일 다운할 때, 기존 노드의 Pod을 다른 노드에 새로 띄우기 전에 그냥 죽여버리는 상황이 발생했습니다.
잠깐이지만 서비스 중단이 생겼습니다.
원인 분석
CA의 drain 동작 원칙
CA는 노드를 제거하기 전에 kubectl drain과 유사한 방식으로 Pod을 축출합니다. 이 과정에서 PDB를 존중해야 하지만, 몇 가지 엣지 케이스가 있습니다.
minAvailable: 1과 replicas: 1의 함정
replica가 1개일 때 minAvailable: 1이면, CA 입장에서는 이 Pod을 어디에도 옮길 수 없습니다.
이 경우 CA는 스케일 다운을 포기하거나, 설정에 따라 강제로 Pod을 제거할 수 있습니다.
특히 –skip-nodes-with-system-pods=false 또는 CA 버전에 따라 동작이 다릅니다.
이동 가능한 노드가 없는 경우
스케일 다운 대상 노드에 있는 Pod을 옮길 다른 노드의 여유 공간이 없으면, CA는 새 노드를 프로비저닝한 후 Pod을 이동시켜야 합니다.
하지만 이 타이밍 사이에 순간적으로 Pod이 없는 구간이 생길 수 있습니다.
해결 방법

# HPA minReplicas를 최소 2 이상으로 설정
minReplicas: 2 # 1 → 2로 변경
# PDB는 minAvailable 대신 maxUnavailable로 표현
spec:
maxUnavailable: 1 # 한 번에 최대 1개까지만 Unavailable 허용
HPA의 minReplicas 를 2로 올리면, 항상 Pod이 2개 이상 유지되므로 CA가 스케일 다운 시 1개를 Evict하더라도 남은 1개가 트래픽을 처리할 수 있습니다.
minAvailable: 1 이 의미 있는 보장이 되려면 실제로 이동 가능한 여유 Pod이 있어야 합니다.

|마무리
이번 최적화를 통해 얻은 교훈을 정리하면, 첫째로 워크로드 특성 이해가 선행되어야 합니다.
Node.js 싱글 스레드라는 특성을 무시하고 CPU를 넉넉하게 주는 것은 비용 낭비입니다.
둘째로 인스턴스 타입은 Pod 스펙과 맞춰야 합니다.
CPU:메모리 비율이 맞지 않으면 한쪽 리소스가 항상 남습니다.
셋째로 CA + HPA는 반드시 함께 써야 합니다.
CA만으로는 Pod 레벨의 탄력성이 없어 트래픽 스파이크에 취약합니다.
마지막으로 PDB와 minReplicas는 쌍으로 설계해야 합니다.
PDB 단독으로는 CA의 모든 동작을 막을 수 없습니다.
이번 개선의 핵심은 “더 적은 리소스로, 더 효율적으로”였습니다.
Node.js 특성에 맞는 리소스 최적화와 HPA + CA 조합을 통해 비용과 확장성을 동시에 잡을 수 있었고,
제 운영 환경에서의 다양한 이슈도 경험할 수 있었습니다.
EKS를 운영하면서 비슷한 고민을 하고 계신 분들께 이 글이 도움이 되었으면 합니다.
감사합니다!

